About Cihui Dictionary Utility
This is the utility for the dictionary in Cihui, or more accurately it is an early prototype of the utility. You have to tolerate its deficiency and lack of performance. Fortunately the average user really has no need of using the Cihui utility. The only ones who need to use it are people who want to customize the Cihui input in a special way, such as changing it to use Cantonese, or people who wants to systematically enter large amount of entries into the dictionary.
The utility acts on the dictionary file and not the in memory dictionary. It is important to remember this fact. That is why it starts out with the standard file dialog to open the input method file. Since the in memory dictionary is also being written to file at shutdown time. It is possible to destroy all the entries you enter from the utility. There are several way you can avoid the problem. One way is to use the utility first thing you boot up, (or if you are sure you have not used the Cihui input at all), and reboot immediately after you are done with the utility. Another way is to turn off the save at shutdown option. Yet another way is do you editing, and go to the Cihui CDEV and hit the REVERT button, this would read the file into memory again, however this would not work if you have add a lot of entries then there would not be enough room to read it back in. You must run the utility under the Chinese system but you should turn off Chinese input.
The utility really have two category of operation. One set is very much in batch mode where you either dump the dictionary to a text file or you read entries from a text file. The other set of operation allows for interactive editing of the dictionary. However, the first set is more general than the second set. The interactive editing only allow access and addition of phrase that follow the rule "if char X has sound ABC1 and char Y has sound DEF2, then phrase XY has sound ABC1DEF2". It does that intentionally so that you can never add an entry by mistake that violates this rule. However, if you want to do something like using FRANCE instead of FA3GUO2, then you have to use the batch mode operation.
Batch Mode Operations
In batch mode, the dictionary entry would have an external form which is the pronunciation followed by the list of phrases followed by a carriage return, as in
![]()
In Cihui 1.8, there is a limitation in the dictionary on how many phrases per pronunciation, with two character phrases, it is about 60 phrases, which should be more than adequate. For single characters, it is about 120 and it is possible to run up to this limit, in that case you have to divide it into two groups on two different lines. All operations in batch mode are rather slow and no attempt is made to optimize it, so prepare for a long wait in these operations.
The export function in the file menu would take your dictionary and write it out to a text file in the above format. However, there is one more complication. There is a Dictionary Romanization and a Text Romanization entry in the file menu, the submenu are PinYin, ZhuYin 2nd Form, Wade-Giles, Yale and ShuangPin. You may also add your own entry. In the default no submenu are selected. This means that the utility does not know what romanization is used in the dictionary and what romanization you want in your text file. So during export it just dump the dictionary out in the same romanization. However if two different romanizations are selected, the utility will translate from the dictionary romanization to the text romanization when exporting. For example, the Cihui you are working with is in PinYin, if you then want to dump the file in Wade-Giles romanization, you select PinYin in dictionary romanization and Wade-Giles in text romanization and then you export.
Now suppose you have some own romanization method that still uses digits as tones, you can add it to the utility this way. Use ResEdit to edit the utility, you will find a number of STR# resources, take the pinyin (or any other one you like) and duplicate it, assign a name to the new resource and then edit each item of the string list, replacing the entrys with the corresponding strings in your romanization scheme. When you run the utility again, you will find your romanization list alongside the others.
The import function takes a text file in the above format and puts it into your dictionary, replacing the original contents. Therefore one possibility of editing the dictionary is to first export it, use a text editor to edit the text file and then import it again. While this utility provides some editing functions, some of the entries cannot be accessed this way and you still have to do it by dumping. Note that in this implementation the import function ignores romanization settings. Suppose you want to change your dictionary from pinyin to Wade-Giles. What you can do is to dump your dictionary as Wade-Giles, then import it back (sometimes some editing is necessary). This way you will get a Wade-Giles input method.
The import function completely replaces your dictionary. If you want to merge the entries from a text file with your dictionary, you can use the "Add From Text Dictionary" menu item. In contrast to the import function, the romanization setting is ignored.
In the above two import functions, the text file must be in a certain format, and the pronunciation of the phrase must be given. Sometimes it is useful when you do not have the pronunciation, but just the phrases and you still want to merge the data into the dictionary without spending a lot of time typing in the pronunciation of each character. You can avoid this by using the°@ "Add Phrase file" menu item. Here you only need the Chinese phrases, the pronunciation is deduced from the dictionary. There are two potential problems. If you have forgotten to put in the pronunciation of the character in the dictionary the utility cannot find it, or if the character has multiple pronunciations it will not know which one to choose. Then you have to make the decision yourself. For reasons of implementation this menu item is only enabled after you have selected the "Show Edit Window" menu item. After you select "Import phrase file" from the menu and you select the text file using standard file dialog, you will get the following modal dialog showing the first phrase in the text file and the deduced pronunciation:

Select the first check box if you want the utility to present this dialog to you for each phrase you enter so that you will get a chance to confirm, modify or skip it. If you don't want to confirm each entry, but still would like to confirm an entry where multiple pronunciations are possible, you select the second check box, otherwise the utility will just pick a pronunciation. If the pronunciation is missing this dialog would also show up and allow you to fill it in, unless the third check box is selected in which case these entries are ignored. After you pick all the options, you click OK to proceed and depending on your options, it may go all the way to the end or come back with a certain entry asking for your opinion. Cancel will abort the process and skip will skip the entry presented to you.
There are at least two ways you can use this function. Suppose you want to use the input method with Cantonese data. Using the export with Romanization scheme would not work for you because the mapping is not the same. You have to supply the Cantonese character pronunciation of every character. But it still would be nice if you could use the phrase data in the dictionary so that you wouldn't have to reenter them. What you do is that you just export your pinyin dictionary. Then you run the utility on your Cantonese data (perhaps starting by importing a Cantonese text file), then use this function to get all the phrases you dumped from you pinyin file. Since the Roman characters in your text file are ignored, you end up getting all the phrases, but now with Cantonese pronunciation. The other way you can use this function is that it regards anything that is a run of Chinese characters as phrases, so any roman character and Chinese punctuation are considered to be phrase separators. Now suppose someone sends you a Chinese article with a lot of interesting new phrases that you like in your dictionary, you can go in and edit the file by throwing away words you don't want and separate out the phrases, then you can run this to enter it into your dictionary.
The Delete from text dictionary operation is the reverse of Add from text dictionary, think of the file you selected by SF is a list of words that you want to delete from the dictionary (instead of a list of words that you want to add to the dictionary). The end result is that words that are in your dictionary as well as in that list will be removed from the dictionary.
There is another use of the delete function. Now suppose you want to find out the list of words you have added to the dictionary, what you can do is take your original list as the subtract list, then after the deletion you are left with the new words you have added. You can them use the export function to dump it out and perhaps give it to a friend. But be careful not to save the result or you have destroyed your dictionary.
Interactive Operations
The interactive dictionary editing features are designed with the following scenario in mind. You have a paper dictionary that is in pinyin order and you want to systematically add the entries into the Cihui dictionary. So if you come to the part of zhong1, then you would be adding zhongguo, zhongwen, zhongdeng etc, where all phrases have the same beginning character. After that you go on the to other characters that start with zhong1, after that those starting with zhong2 etc, and after that zhou1 etc. Because of that, the editing window is organized like such a dictionary. Note that because it takes a long time to initialize this window, this window is not shown on start up and you have to select Show Edit Window to get to this window. The first column is the first character index to all the sounds. The second column is the list of sounds in alphabetical order, when you select a sound, the third column show all the characters with that sound. When you select a character in the third column, all phrases that start with this character will show in column 4. Column 6 is equivalent to column 2 and column 5 is equivalent to column 3, they are used to add characters. You can select a sound by scrolling and then clicking on it, which in turn select a character list in column 5. However, it may take a while to select the right sound. A faster way to do it is to type it in (the typing in does not use the input method, that is why you need to turn off Chinese input for this to work). For example, if you want to get XIN1, you may type X, then I, then N, then 1, then CR, then it should scroll to XIN1. Note that this is timed so that if you hit X and don't do anything for a while, the X is ignored. So if you stopped for a while you should start typing the phrase all over again.
So this is how the editing window looks like:
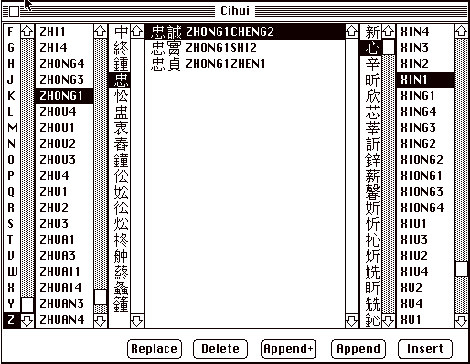
If you now hit the insert button or choose insert from the menu, a new phrase will be composed by concatenating the zhong1 from column 3 and the xin1 from column 5 to form zhong1xin1 the result is:

If now you then select geng on column 5 and click the append button or select append from the menu, the character geng will be appended to the selected phrase zhong1xin1 and the result will be:

If instead of clicking the append button, you click the append+ button or choose the "concatenate and insert" menu item, the zhong1xin1 phrase would stay, in addition there will be a new phrase zhong1xin1geng3:

If you instead click the replace button or choose replace from the menu, the xin1 in zhong1xin1 will be replaced by geng3 resulting in:

Clicking the delete button deletes the selected phrase.
It should be noted that neither the batch operations nor the interactive editing does write to your dictionary file directly. When you want to quit you will be asked if you want to save your changes to the Cihui-dictionary. And again remember that if you are editing the file of an input method that is loaded, that input method may write back to the dictionary at shut down destroying all your efforts with this utility and you should take precaution to prevent that from happening.
Experiments you can do with Cihui
Now that we know some of the things we can do using the utility, let us consider what other possibilities we have to use Cihui. Changing to ZhuYin 2nd form, Wade-Giles and Yale is straight forward, as well as to any other putonghua romanization as long as the tones are not built into the spelling. Using BoPoMoFo is a problem because the current implementation does not support displaying the BoPoMoFo in the input window. Now suppose you are willing to tolerate the use of alphabets in place of BoPoMoFo, can you use Cihui? It still should not be used because it would not perform well. For all the romanization systems, even when there is no consonant some artificial consonant alphabet is used, such as Ying is used instead of Ing, however this is not true of BoPoMoFo, while this is more logical it makes separation of phrases into characters more difficult. However, using Cihui with ShuangPin, where each sound is represented by two letters it should work quite well and it is also close to the spirit of BoPoMoFo.
The digit at the end of each character represents the tone in pinyin. However the interpretation of the digit is completely up to the user. For example using that digit to represents the first digit of the four corner code of the character or some scheme of encoding the first stroke of the character should work very well, especially since the tone digit is optional so that the user does not need to use it if he doesn't want it, but it may be a handy way to discriminate homonyms.
As mentioned earlier, Cihui can be used for Cantonese or other dialect as well. As a matter of fact it does not need to be based on pronunciation at all. For example, we can use it for TsangChi. While it may not be very useful for TsangChi because there is not a lot of "homonyms" in TsangChi anyway, it can still be useful because of the abbreviations, or TsangChi can be simplified to first and last character of TsangChi code, and now we are depending on phrases to reduce the "homonyms". In general, any character encoding code can be converted to be used with Cihui provided the encoding scheme does not use any digits.
Finally by turning off the 'learn phrase' and 'break phrase into character' options. Cihui can even be used with English data although the input may look a bit funny (for example when you want Ni Hao, you have to type YOU GOOD).
In other words, Cihui can be used with a variety of input scheme, be imaginative.
Appendix: ShuangPin
ShuangPin uses two letters to represents a sound, that means if with Cihui homonyms are under control then you can use about 2 keystrokes per Chinese character even without abbreviation, so it is near optimal for input, the drawback is that you have to learn to remember the position of the keyboard so it is not for the casual user. It is based on PinYin. It is fairly popular in China and is one of the input methods in CCDOS. The consonant is idential to PinYin except you use V for Zh, W for Ch and Y for Sh, the pseudo consonants W and Y normally used in PinYin is not used.
For the vowel, the mapping is
- A = a
- B = ai
- C = ao
- D = an
- E = e
- F = ang
- G = eng
- H = ou
- I = i
- J = ie
- K = ei
- L = ong,iong
- M = in
- N = en
- O = o,uo
- P = ing
- Q = ia,ua
- R = ian
- S = uan,uan:
- T = un,un:
- U = u
- V = ui,ue:
- W = iu
- X = iang,uang
- Y = u:, uai
- Z = iao
For those without consonant (include the pseudo one like Y and W), you either use O as the first letter except the following use E
- EL = Yong
- EO = O
- EQ = Ya
- ER = Er
- ES = Yuan
- ET = Yun
- EV = Yue
- EX = Yang
- EY = Yu
All of these is my reconstruction and there may be mistakes.
And the following are my own additions
- EE = Eh
- EZ = Yo
- EB = Yai